mhealthx software pipeline
for feature analysis
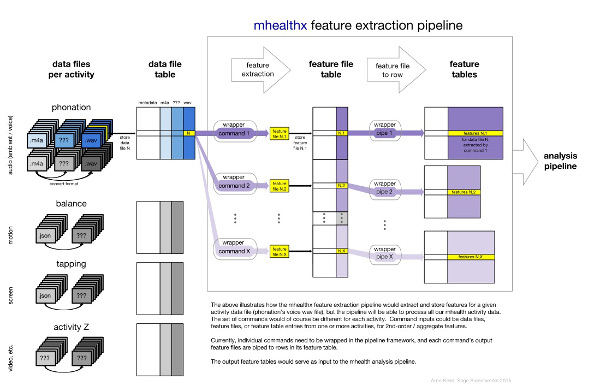
The mhealthx open source software was originally developed to extract low-level features from voice, accelerometry, screen tapping, and other tasks performed on the mPower Parkinson app (see below). The above schematic diagram shows how flexible and modular the nipype-based pipeline environment is, running different software packages to extract and store features from different sensor data for statistical analysis.
Prior experience in mobile health feature extraction and analysis
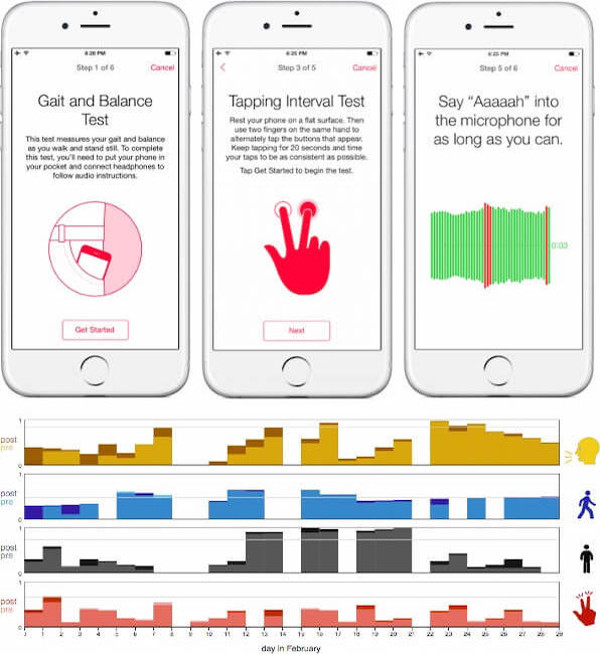
- While at Sage Bionetworks, Arno Klein helped to develop the mPower iPhone app (see screenshots below) on top of Apple’s ResearchKit [2]. This app collects voice data as part of tracking cognitive, behavioral, mood, and physiological states in thousands of people with Parkinson’s disease [3].
- Using the mPower app, we used mobile sensors, feature extraction, and prediction models to estimate individual variation in depression and Parkinson’s disease [1].
- At the Child Mind Institute, we used a portable audio recorder to track progress of children with selective mutism who were enrolled in a group behavioral treatment program designed by the Child Mind Institute [4].
Promise of voice feature extraction and analysis
Extraction and analysis of high-dimensional feature sets to characterize vocal production, speech patterns, and speech content is a promising direction for biomarker identification. Features characterizing vocal production are independent of speech content itself, and can provide objective measures of motor difficulties as well as objective means of assessing relevant psychiatric states, such as mood and anxiety. Features related to speech patterns and content provide additional opportunities to characterize more complex emotional and cognitive states, as well as issues related to processing information and expressing thoughts. For voice feature extraction, mhealthx currently makes primary use of the openSMILE package.
Current state of mhealthx
We have not been actively maintaining mhealthx for some time, but intend to resume development efforts to update and expand its feature extraction capabilities for use with MindLogger and wearable sensor data we will be collecting from future projects.
References
- [1] Ghosh, SS, Ciccarelli, G, Quatieri, TF, Klein, A. (2016). Speaking one’s mind: Vocal biomarkers of depression and Parkinson disease. The Journal of the Acoustical Society of America, 139(4):2193. doi:10.1121/1.4950530
- [2] Bot, B.M., Suver, C., Neto, E.C., Kellen, M., Klein, A., Bare, C., Trister, A.D. (2016). The mPower Study, Parkinson disease mobile data collected using ResearchKit. Scientific Data, 3(March):160011. doi:10.1038/sdata.2016.11
- [3] Chaibub Neto, E., Bot, B. M., Perumal, T., Omberg, L., Guinney, J., Kellen, M., Trister, A. D. (2016). Personalized hypothesis tests for detecting medication response in Parkinson disease patients using iPhone sensor data. Proceedings of the Pacific Symposium on Biocomputing:273–284. doi:10.1142/9789814749411_0026
- [4] Busman, R, Xu, HY, Jozanovic, RK, et al. (2016). Evaluating the efficacy of a targeted behavioral treatment for selective mutism using vocal recording. SMA-UCLA Annual Conference.
