Doctor as data scientist
a high-dimensional view of health
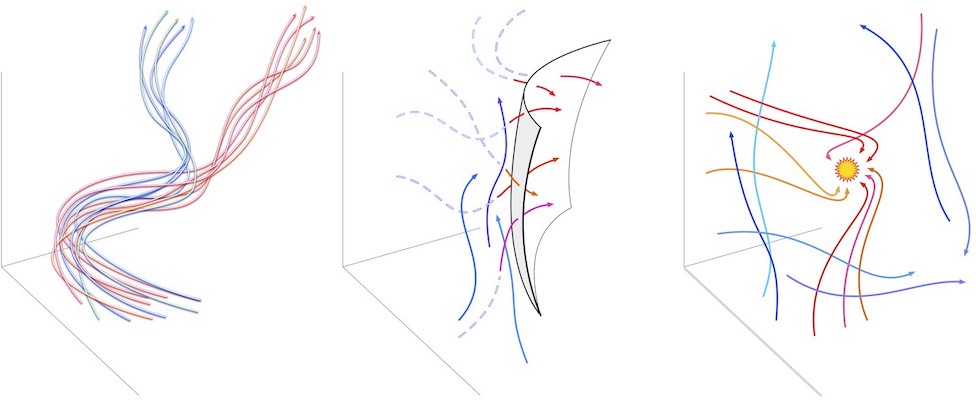
Schematic representations of three hypotheses related to the health state space. Left to right: (A) Similar trajectory hypothesis, (B) State transition hypothesis, and (C) State attractor hypothesis. Only three of many possible dimensions are shown. Each arrow represents a single individual’s trajectory in this 3-D subspace. (A) Similar trajectories (blue or red) lead to similar health outcomes and can be used to compare individuals. (B) Boundaries in the state space determine transitions between healthy (blue) and unhealthy (red) conditions. (C) Attractors in the state space attract approaching (red) trajectories toward particular health conditions.
Schematic representations of three hypotheses related to the health state space. Left to right: (A) Similar trajectory hypothesis, (B) State transition hypothesis, and (C) State attractor hypothesis. Only three of many possible dimensions are shown. Each arrow represents a single individual’s trajectory in this 3-D subspace. (A) Similar trajectories (blue or red) lead to similar health outcomes and can be used to compare individuals. (B) Boundaries in the state space determine transitions between healthy (blue) and unhealthy (red) conditions. (C) Attractors in the state space attract approaching (red) trajectories toward particular health conditions.
The following was also posted on Medium on 10/26/2016.
Arno Klein and Satrajit Ghosh
October 26, 2016
“It is more important to know what sort of person has a disease than to know what sort of disease a person has.” — Hippocrates
Each individual has a unique history that determines his or her health at any given moment. This state of health is affected by myriad influences, such as genetic heritage, environmental exposures, social interactions, medical maladies, evolving ecosystems of microbiota, cognitive and emotional demands, and so forth. And yet it is to the doctor that falls the overwhelming responsibility of surmising state of health from limited observables for any given individual. A doctor has a finite set of experiences to draw from, is subject to the same cognitive fallacies in assessment and decision making as any human, and often must synthesize information from many specialists well outside of the doctor’s expertise. Recommendations about clinical intervention are often based on past studies that collected insufficient detail about its participants to fairly reflect the particular state of a given individual. We describe the concept of a “health state space” with which we will be able to track an individual’s health and compare a trajectory in this space with those of other individuals. We posit that each of us live in a health state space, and that collecting data from and analyzing more dimensions of that space within and across individuals will help patients and clinicians better manage their health and disease.
The health state space: a high-dimensional view of health
If we were to measure a single factor that influences health and plot it along one dimension, then we would have a one-dimensional representation of that aspect of our health. For example, that dimension could represent a measure of weight. Another dimension could be age, another expression of a particular gene, and yet another the frequency of suicidal ideation, and so forth. Taken together, the many dimensions would constitute a high-dimensional “health state space” and any given individual’s state of health could conceptually be represented as a position in this space, as a vector of coordinates. Moreover, since we are changing from one moment to the next, a person’s evolving state of health would be characterized by a path in this space.
There are challenges to dealing with high-dimensional data, which can be sparse and noisy (see “The challenge of many dimensions” below), but the power of this view of health is that one could map millions of people into the same space, to find populations with a similar trajectory through that space, or to define transitions between subspaces. A hypothesis related to the former is that similar trajectories can better predict which actions would lead to better outcomes for an individual. In other words, if one person’s trajectory charts a similar course as the early trajectories of other people, we could potentially extrapolate that person’s trajectory to predict the progression of an illness or the outcome of a given intervention. The “similar trajectory hypothesis” opens up many questions, such as how important absolute location, relative timing, and trajectory shape are for defining similarity among trajectories, keeping in mind that similarity is context- and application-dependent [Hennig, 2015].
A second hypothesis is that similar trajectories are less important in defining health and pathology than the shape of the health state space itself, that boundaries in the space reflect state transitions from health to pathology. This is analogous to transitions from one state to another in finite-state machines or phase boundaries between different states of matter. According to this “state transition hypothesis,” crossing a boundary in the health state space could be accomplished by wildly different trajectories or from a vast number of positions that flank the transition boundary, and depends simply on a local displacement in this space.
A third hypothesis is that rather than boundaries, it is attractors and repellers that act as the primary influence on when and at what rate one gets healthy or sick. Attractors and repellers, from the field of dynamical systems, can be points, curves, manifolds, or more complicated structures. This “state attractor hypothesis” predicts that perturbing along different dimensions would have little influence on position in the health state space if that position is near an attractor in that space. For example, the inexorable decline associated with a neurodegenerative condition may be the manifestation of an attractor in dimensions related to the genetics and physiology of the associated disease.
The similar trajectory, state transition, and state attractor hypotheses are not mutually exclusive. If the three panels of Figure 1 were combined, one could imagine similar trajectories crossing a boundary toward an attractor. To build on the neurodegeneration example, it is conceivable that individuals with a similar medical history (similar trajectories) might suffer an injury or cross a threshold of symptom severity (state transition) before succumbing to the decline (attractor) of the disease. In this model, treatment would redirect a trajectory, alter a transition boundary, or diminish the effect of an attractor.
Current clinical practice: a small slice of the health state space
Doctors probe a small slice of the state of an individual’s health by various means, such as clinical observations, laboratory tests, and exploratory procedures. Clinical observations assess outward signs of health, such as appearance, weight, blood pressure, heart rate, reflexes, neurological exams, and psychiatric evaluations. The benefit of such carefully controlled observations is that they can generate well-structured information that may easily be compared across individuals, and can be used to assert whether an individual lies within the realm of healthy behavior. The major drawback of such observations is that they may not reflect the normal day-to-day behavior of the individual, given that the individual knows he or she is being observed in an artificial context and at a preselected or for a limited period of time. A notable example is the measurement of blood pressure, which can be sensitive to context. Even if context had no impact on the state of a patient, the act of observation is subjective, from deciding whether and how to probe a condition, reading and interpreting the results of the probe, and deciding further actions based on the interpretation. Furthermore, doctors must often supplement their own observations with those of the patient made at home and recalled from memory.
Laboratory tests attempt to overcome concerns about the subjectivity of clinical observations by acquiring more objective measures, often from a single tissue. Examples include a standard blood workup, urinalysis, or spinal tap. While these tests generate numbers associated with underlying physiological parameters, they still require some degree of interpretation.
Exploratory procedures involve the exploration of data collected from a patient. Examples include visual assessment of histology (microscopic analysis of biopsies), electrophysiology (electrocardiograms, electroencephalograms, magnetoencephalograms), and imaging data (X-rays, ultrasound, endoscopy, magnetic resonance images, computerized axial or positron-emission tomographs). Exploratory procedures augment or replace a doctor’s clinical observations with a technician’s performance of a procedure, where the technician’s expertise is in the use of the examination equipment. Unlike laboratory tests, which acquire a limited set of measures that are often standardized, exploratory procedures generate rich visual or time series data that require a greater degree of subjective visual assessment or processing by, for example, a radiologist.
Mobile health data to fill the health state space
Mobile devices (such as smartphones and wearable computing devices) and off-body surveillance equipment (smart homes and more generally the “Internet of things”) provide the potential for collecting health-related information while overcoming the problems of expense, inconvenience, and infrequency shared by clinical observations, laboratory tests, and exploratory procedures. Hundreds of millions of people use applications on mobile devices, which can be free to use any time and wherever the person happens to be, can collect self-reported data such as traditional clinical surveys, and have the potential with cameras and microphones to engage experts in remote assessments of personal health, or “virtual house calls” [Dorsey, 1993]. Standard smartphones also come with other sensors, including accelerometer, gyroscope, and GPS for estimating motion and position, and a touch screen for interactive tests of timing, dexterity, memory, and other cognitive tasks. The number of different types of sensors will only increase over time, and will either incorporate or complement the sensors already offered in wearable fitness trackers that measure heart rate and variation, and skin temperature, moisture, electrical impedance, etc. While it is unlikely that such sensor-based measures will supplant existing standard health measures in the near future, much research will be devoted to validating combinations of such measures against these standards [Friend, 2015]. Validation may be aided in the future by lab-on-a-chip microscopy, chemistry, and genomics tests through advances in microfluidics and microelectronics [Komatireddy, 2012].
While some signals from sensors may directly correspond to the types of measures of current interest to clinicians, there are opportunities for far more detailed and indirect assessments of health. For example, social logs (frequency, duration, and variety of social exchanges, without reference to their content) can be used to infer degree of socialization. Accelerometer or GPS data can provide information about changes in location that can further help to infer degree of reclusiveness. While tone and word frequency can be used to infer mood states, the same can also be accomplished from passive monitoring of smartphone usage [LiKamWa, 2011]. Even deeper inferences about mood and cognitive state are possible when taking into account content of social exchanges, even as a scrambled “bags of words.”
It is easy to imagine relating inferences made from social logs or word frequencies to a human analyst making inferences about someone’s health. The analytical possibilities become much more interesting as the sensor-derived signals become far too complex for a human to interpret. For example, accelerometer and voice data can be converted into literally thousands of low-level features, and the sheer scale of the data can be immense if collected passively throughout the day. Taken further, features derived from sensor data may be used to inform biological, emotional, and cognitive models, and these models could in turn be used to predict states of health that have yet to be measured for a particular individual.
N of 1 studies
Early adopters of sensor-based personal health data collection include individuals interested in tracking their fitness, and in members of the “quantified health” movement, who actively promote personal data capture. While some may disregard attempts at conducting personal studies as anecdotal or “n of 1” studies, this view is short-sighted for several reasons. First, these individuals act as alpha testers of the type of health tracking equipment we may all wish to avail ourselves of some day. Second, case studies have historically characterized new medical conditions, and recording these early observations may prove invaluable to tracing the etiology and epidemiology of a condition. Third, rare conditions may never be exhibited in a large enough population to satisfy a clinical study, but nonetheless may be informative among the few cases that do exist. Finally, if we are to embrace the concept of a high-dimensional health state space, we must acknowledge that the probability of two people being situated in exactly the same position in this space, or following precisely the same trajectory in this space is very small, and so everyone’s health is effectively an “n of 1.”
One danger in conducting personal data collection is that the mere act of recording one’s own health can result in greater self focus and an increase in symptoms [Ferrari, 2010]. For this reason, it is important to ensure that data collection is performed in as impartial a manner as possible for a more detached assessment, preferably by a third party or in a passive and automated manner. Given that an impartial observer’s assessment of psychological state can be more accurate than the observed party’s assessment, it is possible that software algorithms may one day be more accurate in a variety of assessments of personality and health without relying on self reports [Youyou, 2015].
Mobilizing health data collection in a large population
While we can learn from the efforts of early adopters of personal health data collection, there is a far greater opportunity to define and build a health state space if such efforts were scaled up across a large population, whether aggregated across individuals or shared among members of a community (such as PatientsLikeMe.org) [Chou, 2013]. Only then will it be possible to compare an individual’s data with many others’ data, to test the similar trajectories hypothesis, and to infer the existence of boundaries and attractors in the health state space (the state transition and state attractor hypotheses). But to make these comparisons, the data must be accessible, and therefore preferably assembled in open and public repositories for wide access by researchers.
An example of large-scale mobile health data collection is our “mPower” Parkinson disease symptom tracking research study (parkinsonmpower.org). The corresponding app was one of the five initial apps using Apple’s open source ResearchKit platform (apple.com/researchkit) for IRB-approved medical research applications. In its first three months it collected data from tens of thousands of participants [Bot, 2016], demonstrating the reach of smartphones and the eagerness of the public to be involved in research studies. Parkinson disease is a neurological disease with a complex constellation of symptoms that affects millions of people, and is a reasonable focus of a mobile health study for two primary reasons. First, in spite of the disease’s complexity, the routine standard of care for monitoring its progression is still a doctor’s appointment, where the doctor administers a standard survey and assesses the patient’s performance via a small number of tasks that can be translated to an app. Second, due to cost and inconvenience to the patient, doctors’ appointments are months apart, making it nearly impossible to objectively monitor patients’ symptom progression with any meaningful frequency in the conventional manner. mPower uses a mix of standardized Parkinson-specific surveys and tasks that activate phone sensors to collect and track symptoms related to voice, memory, dexterity, balance and gait. The frequent, low-cost, longitudinal tracking afforded by mobile health sensors offer an unprecedented ability to track an individual patient’s symptoms over time and across conditions, such as before and after medication [Neto, 2016].
While the potential of mobile health technologies is impressive, a danger arises when technologies create solutions that are not matched to real patient needs. Mobile phone apps such as mPower collect survey and sensor data explicitly associated with a defined condition, but are necessarily biased to collect information their medium enables. For example, the mPower app presents questionnaires such as the unified Parkinson disease rating scale [Movement Disorder Society, 2003] and collects accelerometer data to relate motor disturbances to symptom severity. However, standardized surveys are intended to generalize, not personalize, and motor disturbances may be far less important to patients’ lives than the “soft symptoms” of Parkinson disease such as cognition and mood [Stamford, 2015]. The future of mobile health will collect information along many more dimensions than are deemed relevant to a particular condition, not just to increase the dimensionality of the health state space, but to make it possible to make comparisons across people and conditions, and to redefine the conditions themselves.
The challenge of many dimensions
Clinical observations, laboratory tests, and exploratory procedures can contribute part of the picture of a person’s state of health, and mobile health technologies offer the tantalizing potential to contribute so much more, so it is natural to ask why one wouldn’t simply conduct all of the above for a more complete picture. Even if one could overcome the burden, expense, and possible harm that could come from conducting a multitude of tests in a clinic or via apps, there are two principal problems related to analysis and interpretation of multiple tests.
The first, called “the multiple testing problem,” can be described with the following example. When you get your blood drawn, if you request that many tests be conducted to see if you have one problem or another, then the probability increases that a healthy blood sample will come up positive for one or more of these tests. These false positives can be mitigated by requiring a higher significance threshold for the individual tests to compensate for the number of tests being conducted, to increase the number of samples per test, or to limit the number of tests. In clinical practice, multiple tests are often conducted on a single sample (such as a single blood draw), resulting in more false positives, which can lead to more procedures, more diagnoses [Black, 1993, Welch, 2011], and overtreatment [Brownlee, 2007]. These examples assume, however, that each dimension is an independent marker for illness, whereas a high-dimensional view of health expects there to be high-order dependencies (complex relationships) among the different dimensions [Ellis, 2014]. While this makes data analysis a more complicated endeavor, such analyses are far less prone to considering any one dimension to be a positive indicator for illness. The entire problem is circumvented if one were to conduct a single test on multiple dimensions rather than multiple tests on separate dimensions.
The second, and more difficult problem, is the “curse of dimensionality” [Wikipedia, 2015], well known among data analysts and statisticians, where obtaining a statistically reliable result requires an exponential growth in the amount of data needed to support the result with an increase in number of dimensions. If we consider the high-dimensional health state space introduced above, as one increases the number of dimensions used to characterize state of health, the space increases in volume and the data become very sparse. To compensate for this, one would need to acquire a lot of data and simultaneously also reduce the dimensionality. Current smartphones again offer convenient, even automated ways of collecting data, are in the pockets of hundreds of millions of people, and are beginning to generate data in large-scale medical research studies. There are many mathematical approaches to reducing the dimensionality as well, but no general solution yet exists.
To summarize, the challenge of many dimensions is often addressed by reducing the number of tests or by increasing the amount of data. These are complementary, as the number of questions one can ask of the data increases with the amount of data, and conversely, the significance of results increases for a given amount of data with fewer questions. One way of reducing the number of questions is to reduce the number of dimensions, by extracting salient features from the data. Machine learning and deep learning methods are under very active development to analyze large numbers of features or large amounts of raw signals, and may independently corroborate the hypotheses above, or provide new perspectives on the underlying structure of the health state space.
Summarizing the health state subspace for future clinical use
While the concept of a high-dimensional health state space could be useful to researchers and data analysts, the concept may be too abstract and contain too many quantities to be of use for a clinician or patient. For this concept to find utility in the clinic, a synopsis or truncated form of this state space must be constructed for ease of comprehension and communication. There are three common ways to reduce the number of dimensions in a data set: feature selection, aggregation, and transformation. Feature selection is the most straightforward — select a subset of dimensions and discard the rest. Determining which features are more important for a given application is currently a very active area of research. Aggregation involves the simple combination of some dimensions, or binning of data. For example, the tens of questions in a questionnaire can be summarized as a single score for brevity. Transformation is the more general process of mapping features to another space with fewer dimensions. Principal component analysis is a common statistical approach that converts a set of possibly correlated dimensions into a set of linearly uncorrelated dimensions, for example.
An alternative to reducing the number of dimensions is to reduce the number at a given time. In what is referred to as a “grand tour visualization,” a high-dimensional data set is projected onto 2-dimensional subspaces and presented in succession to a human viewer to look for patterns in the data [Asimov, 1985]. In an analogous sense, a “health state subspace” or “health state projection” could present a data-driven selection of health dimensions to a doctor / data analyst. Until we know enough about the health state space to select the most clinically relevant dimensions for a given condition, selections could be made based on anomalies in a given individual or on similarities to others before they have undergone treatment. Just as a doctor currently presents the results of a blood workup as a set of quantities to a patient, one day a doctor as data analyst could present these and other quantities from a variety of other sources to a patient for a more complete picture of their state of health.
Clearly, considerable research will need to be conducted to generate appropriate features, to cull less relevant features, and to identify relationships among these features when constructing an individual’s health state subspace. Even more work lies ahead in overcoming culturally ingrained expectations of simple mappings between a predefined medical condition and a handful of symptoms, such as “heart disease” and “high cholesterol” or “autism” and “perseveration.” This will require a more complex and nuanced view of health and the many factors affecting it. Subjective assessments of our own past, present, and future condition can impact our health and must also be accounted for by the state space for the space to have practical and personal relevance.
When doctors and patients are able to communicate about health for what it is, an evolving, high-dimensional state for which we are constantly gathering data, then we will have entered a world where we can all play a role in helping to improve our understanding of our health, and act on that understanding to improve our health.
Acknowledgments
The authors thank Dr. Howard Schubiner for valuable feedback on an early version of the manuscript.
References
Asimov D. 1985. The Grand Tour: a tool for viewing multidimensional data. SIAM Journal on Scientific and Statistical Computing 6(1):128–143. DOI:10.1137/0906011
Black WC, Welch HG. 1993. Advances in diagnostic imaging and overestimations of disease prevalence and the benefits of therapy. New England Journal of Medicine 328:1237–1243.
Bot BM, Suver C, Neto EC, Kellen M, Klein A, Bare C, Doerr M, Pratap A, Wilbanks J, Dorsey ER, Friend SH, Trister AD. 2016. The mPower Study, Parkinson Disease Mobile Data Collected Using ResearchKit. Scientific Data 3, Article number: 160011. DOI:10.1038/sdata.2016.11
Brownlee S. 2007. Overtreated: Why Too Much Medicine Is Making Us Sicker and Poorer. Bloomsbury USA (New York).
Chou WS, Prestin A, Lyons C, Wen K. 2013. Web 2.0 for Health Promotion: Reviewing the
Current Evidence. American Journal of Public Health 103(1):e9-e18.
Dorsey ER, Venkataraman V, Grana MJ, Bull MT, George BP, Boyd CM, Beck CA, Rajan B, Seidmann A, Biglan KM. 2013. Randomized controlled clinical trial of “virtual house calls” for Parkinson disease. JAMA Neurology 70:565–570.
Ellis SP, Klein A. 2014. Describing high-order statistical dependence using “Concurrence Topology,” with application to functional MRI brain data. Homology, Homotopy and Applications. 16(1): 245–264. DOI:10.4310/HHA.2014.v16.n1.a14
Ferrari R, Russell AS. 2010. Effect of a symptom diary on symptom frequency and intensity in healthy subjects. Journal of Rheumatology 37(11):2387–2389. DOI:10.3899/jrheum.100513
Friend SH. 2015. App-enabled trial participation: Tectonic shift or tepid rumble? Science Translational Medicine 7(297):297ed10. DOI:10.1126/scitranslmed.aab1206
Hennig C. 2015. What Are the True Clusters? Pattern Recognition Letters 64: 53–62. DOI:10.1016/j.patrec.2015.04.009
Kantz H, Schreiber T. Nonlinear time series analysis, 2nd ed. Cambridge University Press, Cambridge (2006).
Korein J. What is your dangerous idea? Edited by John Brockman. Simon and Schuster (2007).
LiKamWa R., Liu Y, Lane ND, Zhong L. 2013. Moodscope: Building a mood sensor from smartphone usage patterns. In Proceeding of the 11th annual international conference on Mobile systems, applications, and services (pp. 389–402). ACM.
Komatireddy R, Topol EJ. 2012. Medicine Unplugged: The Future of Laboratory Medicine. Clinical Chemistry 58(12):1644–1647. DOI:10.1373/clinchem.2012.194324
Movement Disorder Society Task Force on Rating Scales for Parkinson’s Disease. 2003. The Unified Parkinson’s Disease Rating Scale (UPDRS): status and recommendations. Mov Disord 18:738.
Neto EC, Bot BM, Perumal T, Omberg L, Guinney J, Kellen M, Klein A, Friend SH, Trister AD. 2016. Personalized hypothesis tests for detecting medication response in Parkinson disease patients using iPhone sensor data. Pacific Symposium on Biocomputing. 21:273–284. PMID:26776193. DOI:10.1142/9789814749411_0026
Stamford JA., Schmidt PN., Friedl KE. 2015. What Engineering Technology Could Do for Quality of Life in Parkinson’s Disease: a Review of Current Needs and Opportunities” IEEE Journal of Biomedical and Health Informatics (accepted). DOI:10.1109/JBHI.2015.2464354
Welch HG, Schwartz L, Woloshin S. 2011. Overdiagnosed: Making People Sick in the Pursuit of Health. Beacon Press (Boston).
Wikipedia. 2015. “Curse of dimensionality.” Wikipedia: The Free Encyclopedia. Wikimedia Foundation, Inc. 22 July 2004. Web. 22 Oct. 2015.
Youyou W, Kosinski M, Stillwell D. 2015. Computer-based personality judgments are more accurate than those made by humans. Proceedings of the National Academy of Sciences 112(4):1036–1040. DOI:10.1073/pnas.1418680112