MindLogger: A Digital Platform for Shareable Access-Controlled Ecological Data Collection and Storage in MongoDB Atlas
New York Hilton Midtown
New York, New York, USA
Jon Clucas
June 18, 2019

I'm Jon Clucas, based in the MATTER Lab at the Child Mind Institute, just a few blocks from here in Manhattan. The Child Mind Institute is an pediatric psychiatric organization comprised of a for-profit clinic and a not-for-profit research and outreach institute. Most of the research at the Child Mind Institute is is based in neuroimaging, but the MATTER Lab, where I work, focuses on ecological data and intervention, "ecological" meaning "in the wild" or "where people are without our intervention."
In this presentation, I'm going to talk about a product we're actively developing to help ourselves and others collect ecological / in-the-wild data and to afford interventions in those natural settings. I'll describe the problem we're working to address, the applications we're building, our initial use cases, how and why we're using MongoDB, our schemata, and our user roles which I'm presently working on implementing.

This photo is of an actual file cabinet at the Child Mind Institute, filled with physical forms used in collecting assessment data for clinical patients and research participants. Typically, a person being assessed needs to come to a location with such a form, or someone with such a form needs to bring that form to the person.
Even when these assessments are collected digitally or are digitized after collection, so many data standards are in use in so many different contexts that essentially no standards have risen to the status of accepted conventions.

The product we are developing to address this problem is a framework of open-source mobile and browser-based applications that use community=generated semantically defined schemata and read data from and feed data to a common MongoDB instance.
The mobile app is available on both iOS and Android, and the web app should work in any current browser.
Here is an example of the web app in action. The mobile app has comparable functionality, but in a height > width aspect ratio. Once a user is logged in, that user can click into any applet available to him/her. The applet I'm showing here includes just two activities in its activity set: "Morning" and "Evening". This applet also includes an explanatory screen that the user sees before starting his/her activities.
The first question, asking about time in bed, gives me two time choosers and calculates the duration before I submit.
The second question is a simple yes/no question, as is the third.
After completing the activity, the app saves my responses to the database, thanks me, and I can move on to another activity or quit.
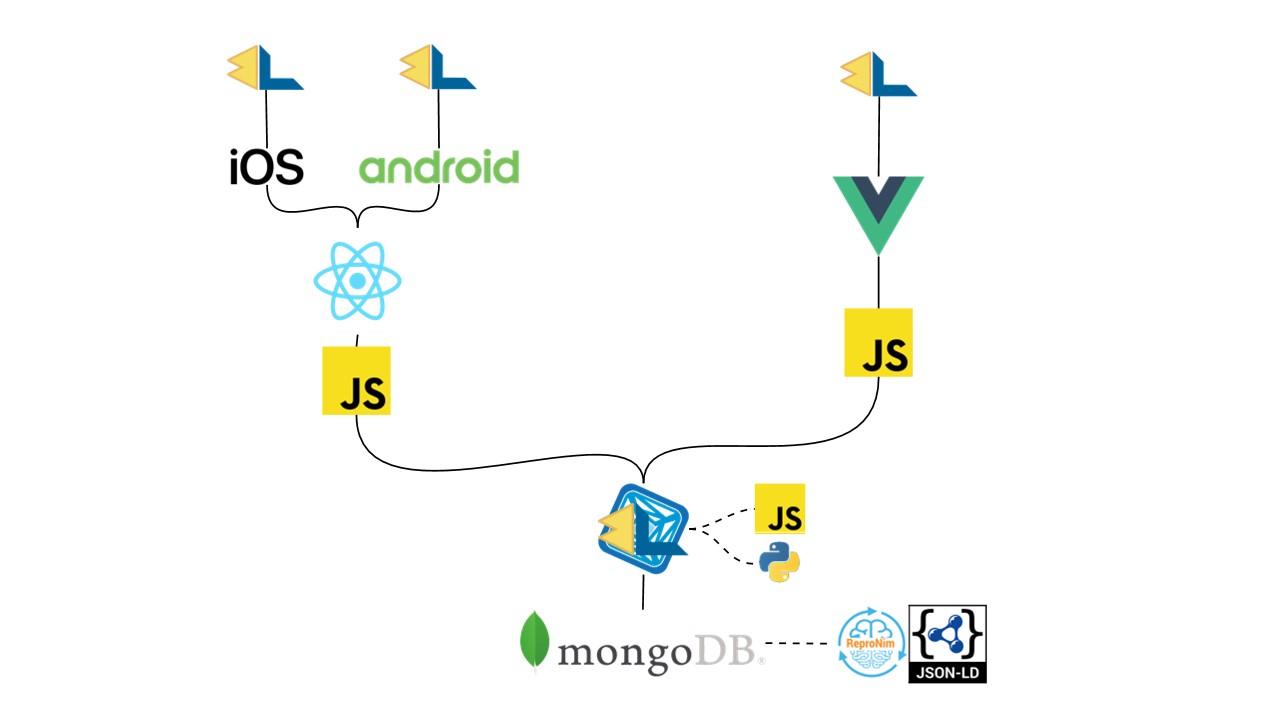
Our solution stack for MindLogger is shown in this diagram. The mobile apps are compiled into native iOS or Android code through React Native in JavaScript. The web app is also JavaScript, using Vue.
For the API layer, we've been customizing a framework from Kitware called Girder; ours is Girder for MindLogger. This layer is written in JavaScript and Python.
Finally, our data are stored in MongoDB, specifically in MongoDB Atlas. With our ReproNim colleagues at MIT, we're co-developing a semantic schema in JSON-LD. Since MongoDB natively stores BSON, we can store data saved in our schema without any translation or refactoring.

As soon as we started developing MindLogger, we started getting expressions of interest from a variety of collaborators. Our initial use cases come from
- our own research and research of a variety of collaborators,
- the clinic at the Child Mind Institute,
- schools and
- quantified self developers.
Each of these collaborators plays a role in initiating, planning, developing, testing and prioritizing the features in MindLogger.

Under the hood, all current versions of MindLogger are served through a customized API with data living in MongoDB Atlas. I'll speak now about the motivation for this stack, then some technical details.
This slide shows nine ambitious projects my team, the Child Mind Institute MATTER Lab, is developing. At the time I put these slides together, we had 74 active repositories on GitHub. That number is now closer to 80.

This slide shows the core team of the MATTER Lab. At the moment, we are geographically diverse. Arno is in Austin, Texas giving a presentation. Anisha is based at our west coast office in the San Francisco Bay Area. Curt splits time between our Midtown Manhattan office and his offsite fabrication workshop in Queens. I'm here presenting to you. Jake is in Nebraska for medical school, and Anirudh is wrapping up his PhD in Paris, France.

This slide shows the core team of the MindLogger project. For context, my benchmark for a current best-in-class for a platform like MindLogger is Qualtrics which has over 2,000 team members and over a decade of development time and was purchased by SAP last fall for $8 billion.
With three core team members, less than two years of development time, and a budget much less than $8 billion, we rely on tools and services that afford rapid prototyping and low conversion costs.
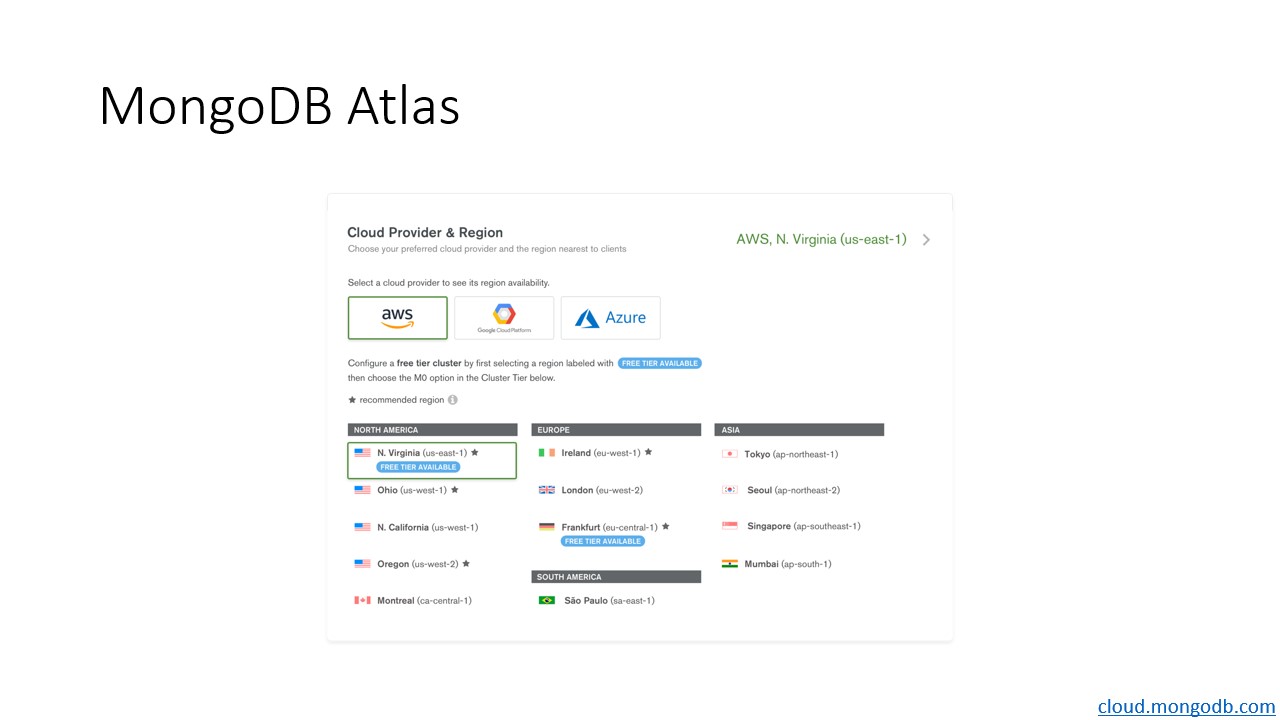
MongoDB Atlas deployment can be as simple as a click-through GUI, as shown in this screenshot. I, my team, lab, and company all hold a strong open-source ethos and strive to make our products portable with minimal switching costs. MongoDB Atlas, through its GUI, allows an administrator to choose between Amazon Web Services, Google Cloud Platform, and Microsoft Azure for cloud hosting, both when setting up a cluster and when migrating.
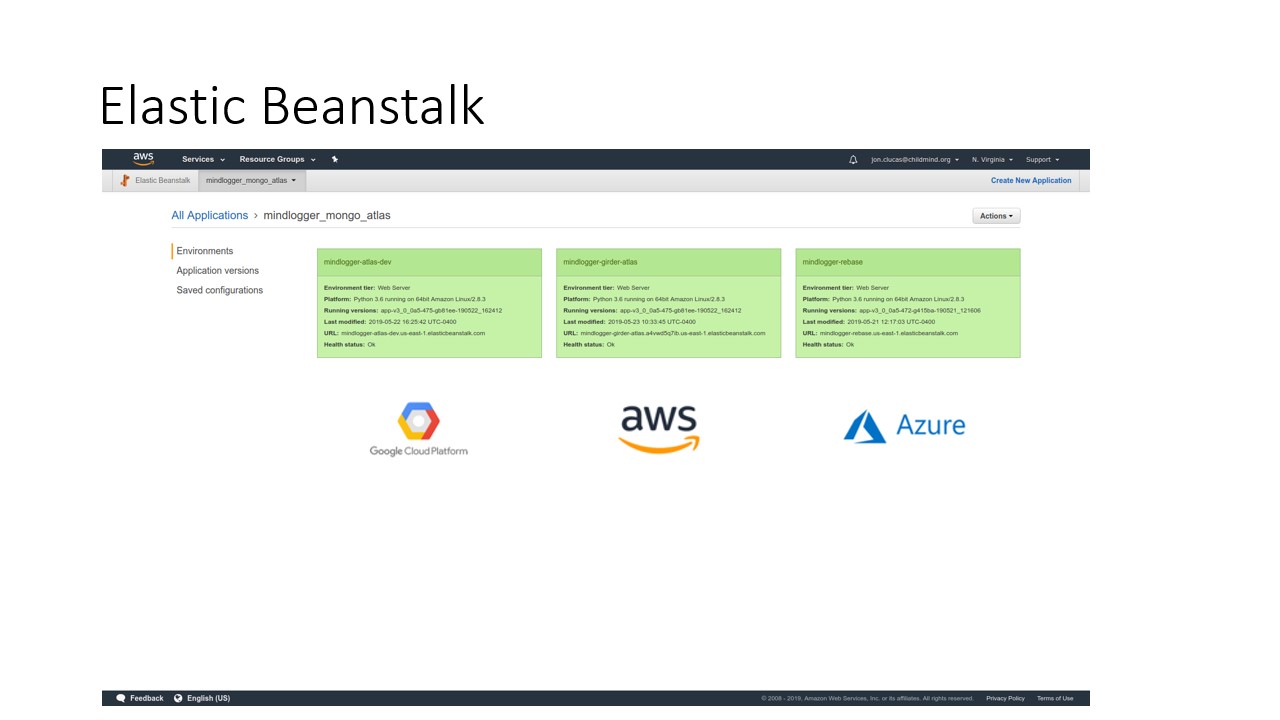
For MindLogger, we have three parallel stacks, each with a MongoDB Atlas cluster hosted on a different cloud to ensure that our configuration is generic enough to run on an administrator's cloud of choice or a local server. For now, all of our Girder instances are hosted on Amazon's Elastic Beanstalk, but our development database is in Google's cloud, our production database in Amazon's, and our sandbox database in Microsoft's.
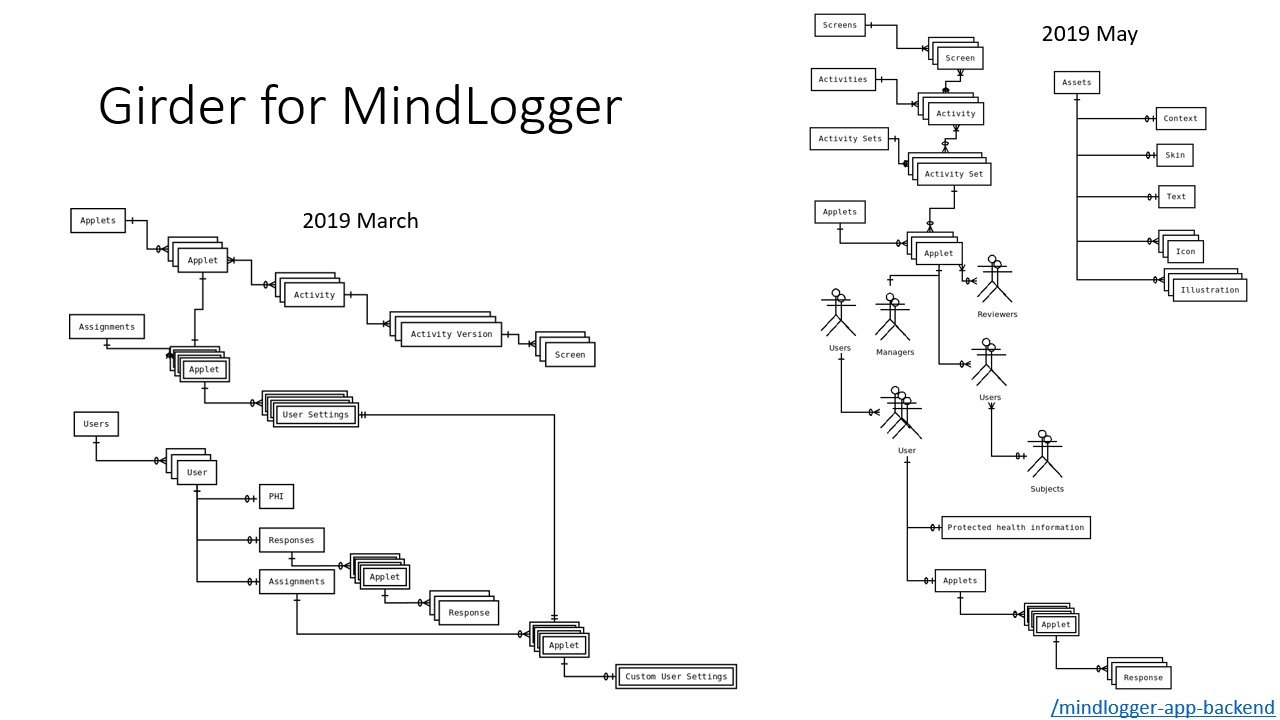
On the left is an entity-relationship diagram showing MindLogger's schema as of this March; on the right is MindLogger's schema as of this May. As you can see, the project is complex and rapidly changing. Our first prototype used a custom PostgreSQL database that was effectively a document store: the primary entities were stored as JSON Objects in their tables.
Moving to a document-oriented database, speicifically MongoDB, we've been able to update our schemata more-or-less independently of our application front-ends by leveraging a RESTful API and the flexibility of document-embedded schema.

One of the selling points of Girder, Kitware's middleware that provides a customizable API, is its on-by-default inclusion of Swagger documentation generated from the code itself and comments within. Like MongoDB Atlas, afforded expedience was a key determinant in selecting Girder to customize for MindLogger. As we move toward a stable v1.0 release of MindLogger, we may migrate from Girder to MongoDB Stitch which has matured a great deal simultaneous with the development of MindLogger.

Our underlying data schema is a work in progress, codeveloped with the ReproNim team at MIT. One of the biggest specific problems with the general problem of paper-and-pencil assessments is the ironic dearth and overabundance of standards. Many users of psychological assessments adhere to one or more competing standards, but without any widely accepted conventions, no standard is effective as a standard.
The ReproNim schema is designed in Resource Description Framework so that users and administrators of assessments can leverage Linked Data tools to relate data collected from related asssessments in a semantically meaningful way. ReproNim schema is defined and serialized in JSON-LD, so translating to and from BSON (MongoDB's native storage format) is trivial.

The example that I clicked through earlier in the presentation is encoded in ReproNim schema. That activity set is visualized horizontally here, showing metadata about the activity set, "Healthy Brain Network: EMA", and the sequence and visibility of the activities within the activity set.

This slide shows the head of the same data as the Visualization on the previous slide, but in the format in which the data are stored. The @context key in this Object has a value of an Array of dereferenceable Internationalized Resource Identifiers (IRIs) that each contain contextual definitions necessary to expand this JSON Object into a well-defined RDF document.

This slide shows the head of the same Object as the previous two slides, but with its @context expanded. Once expanded, each key and value should be either a literal, a dereferenceable IRI, or a JSON-LD keyword.

The activity that I demonstrated earlier, "EMA: Morning", is visualized here, expanding from the ema_morning_schema node in the activity set visualized earlier. Like in the activity set, the activity contains metadata like "preferred label" and "description" and contains order (ie, sequence) and visibility nodes under a ui node. In this case, the order is time_in_bed, nightmares, sleeping aids, and the visibility of each is true.
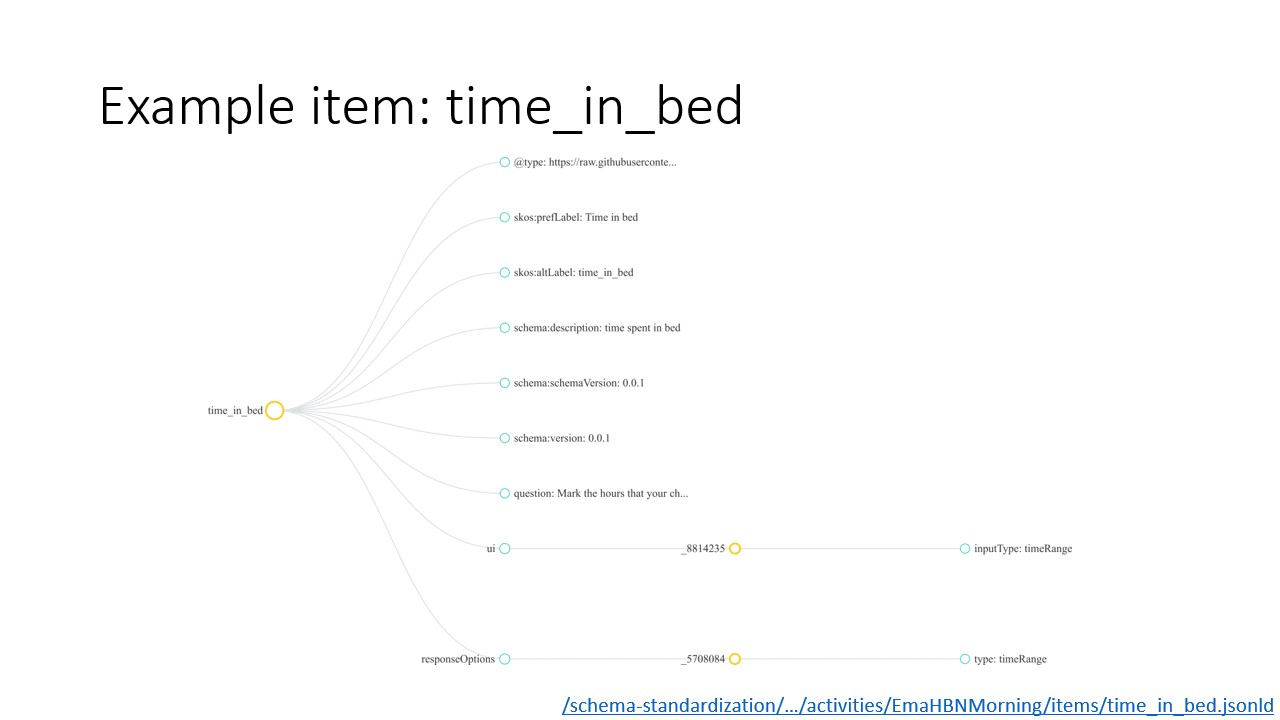
The first item in the "EMA: Morning" activity is time_in_bed, visualized expanded here. Again, we have metadata including "preferred label" and "description", and we have a `ui` node that includes information about how prompts are displayed to the user. In this case, the user has a single timeRange inputType and responseOptions and a question, "Mark the hours that your child was in bed".
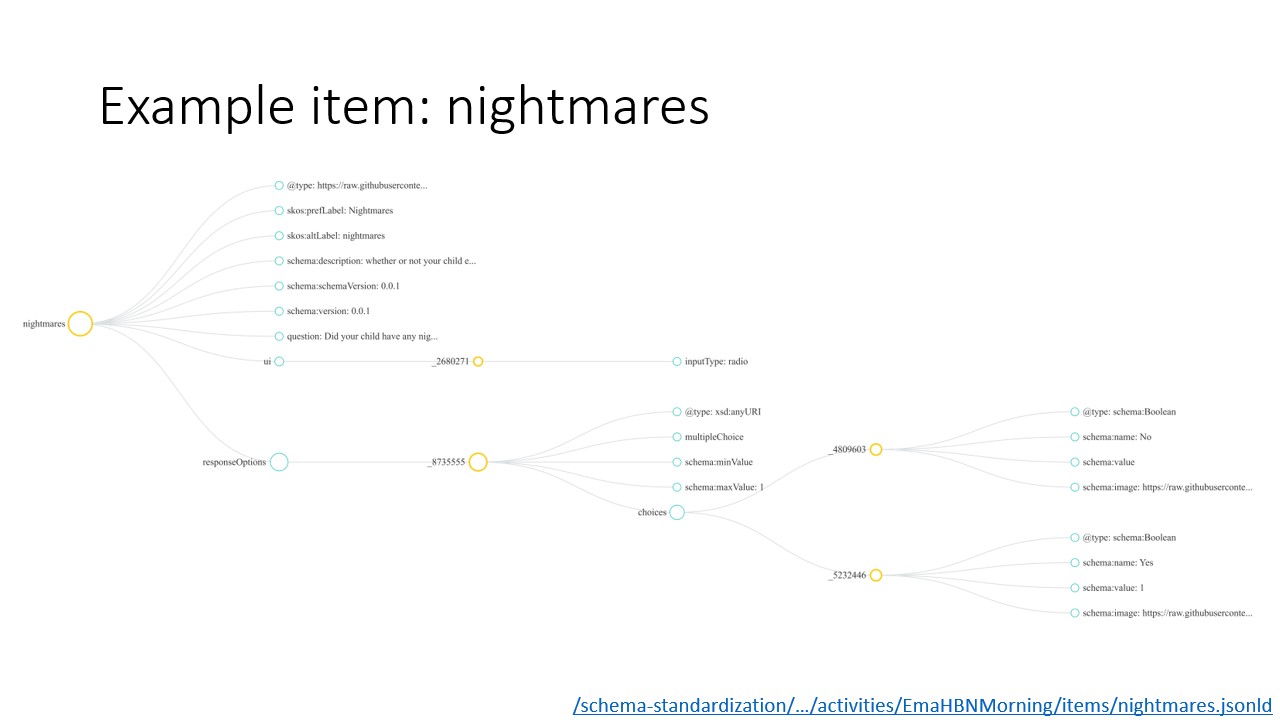
The second item in the "EMA: Morning" activity is nightmares. Again, we have metadata including "preferred label" and "description", and we have a `ui` node that includes information about how prompts are displayed to the user. In this case, the user has a single radio inputType, with two choices ("No" and "Yes") and a question, "Did your child have any nightmares or night terrors last night?".
The final item in the "EMA: Morning" activity is sleeping_aids. Since that item is also a two-option multiple choice question, sleeping_aids has the same keys as nightmares. Its structure is the same as the structure displayed on this slide with different values for the keys.

We currently have working interfaces for a basic set of user interactions and are actively developing complex user management capabilities. We have a variety of stakeholders with a variety of needs, ranging from an n-of-one share-with-no-one use case to fully open sharing, with informants who may or may not be the subject of an activity, and where informants may share subjects. Our in-house use cases include patients and participants for whom multiple specific individuals (eg, themselves, their parents, their doctors, their teachers) should be able to inform about them, and for whom a different, partially overlapping set of specific individuals should be able to see mutually distinct sets of those responses (eg, researchers should not get identifiable information, but doctors should).
Currently our user management is overly restrictive by design. As administrator, I can currently access and modify permissions on everyone's data, but otherwise each user can only access his or her own data. Once we have minimally satisfactory complex controls, we'll adjust so that even administrators cannot access or modify permissions that they have not been granted by the user who owns the data. We'll also be using MongoDB's new client side field level encryption.
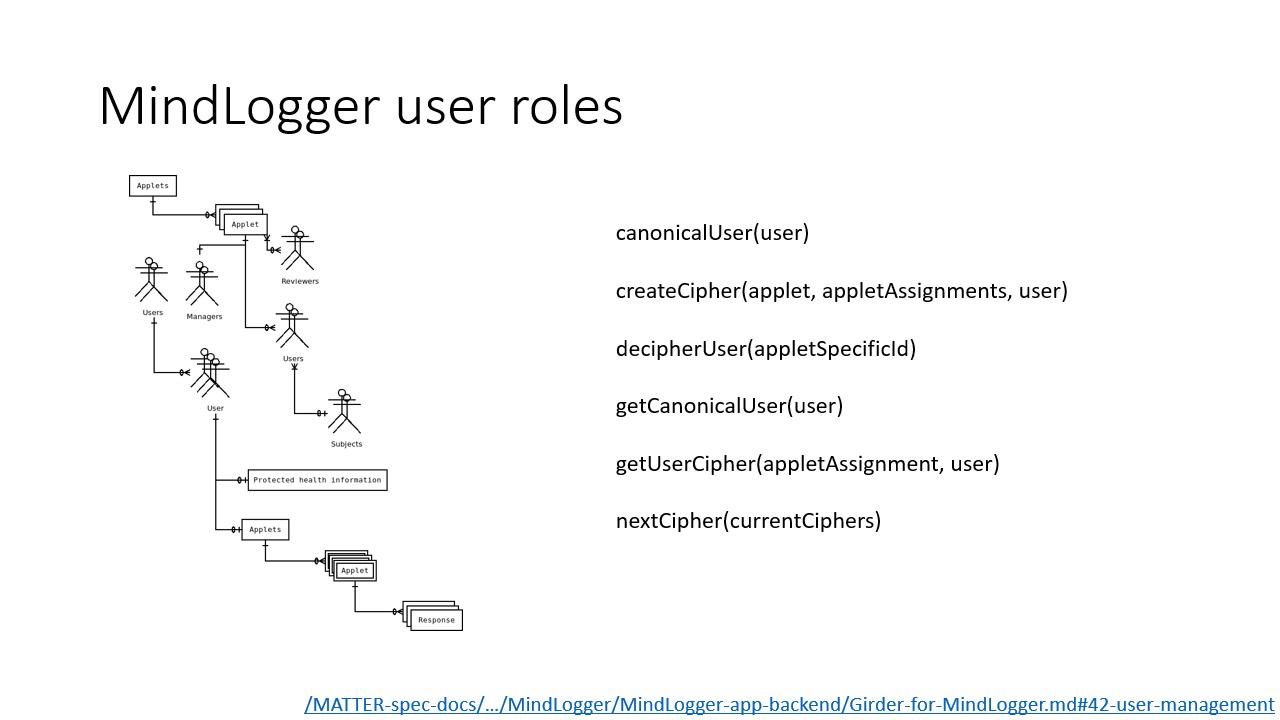
To facilitate our complex user management, we've written a set of functions to cipher and decipher user IDs such that a unique ID is given to a user at any level at which permissions can be set. Only users with permissions at that level on both of two objects belonging to the same user can see that those two objects in fact belong to the same person. The deciphering all happens server-side; the API never exposes a private user's canonical user ID to anyone but the user themself.

If you'd like to try these apps for yourself, you can get the mobile apps at mindlogger.org/download [mindlogger.org/download] and use the browser-based web app at web.mindlogger.org. I do stress that these apps are very much in development and not yet practical for their intended use cases. If you'd like to contribute to or clone any part of this project, each component lives in the Child Mind Institute GitHub organization.